Mastering Real-Time Object Detection with TensorFlow

With advances in computer vision and deep learning, machines are gradually gaining the ability to see and understand visual inputs. One important computer vision task is object detection - locating and identifying objects within images or video frames. Object detection has wide applications, from autonomous driving to medical imaging.
In this article, we will delve into real-time object detection using TensorFlow, Google's open-source machine learning framework. We will discuss different object detection approaches and model-building workflows and demonstrate how to perform object detection by leveraging TensorFlow's powerful object detection API.
What is Object Detection?
Object detection refers to identifying and localizing objects of а certain class (such as humans, vehicles, furniture, etc.) in digital images or video frames. The goal is to determine what objects are present in the image along with their locations using bounding boxes. A good object detection model should be able to accurately detect multiple objects of different classes while handling partial occlusions, scale, and orientation variations. Object detection is а fundamental and challenging computer vision problem with applications across various domains like autonomous vehicles, medical imaging, robotics, surveillance, etc.
Approaches to build Object Detection Model
There are different approaches to tackling the object detection problem using deep learning models. Some of the commonly used techniques are:
One-stage Detectors
One-stage object detectors like YOLO (You Only Look Once) and SSD (Single Shot Detector) perform object detection in а single feedforward convolutional neural network (CNN) pass. They are faster than two-stage detectors but often have lower accuracy. YOLO divides the image into grids and predicts bounding boxes and class probabilities for each grid cell. SSD modifies the convolutional feature map to directly predict classes and boxes.
Two-stage Detectors
Two-stage detectors like R-CNN (Regional CNN), Fast R-CNN, and Faster R-CNN first generate region proposals that may contain objects and then classify and refine the boxes. They are slower but more accurate than one-stage detectors. Faster R-CNN uses а region proposal network (RPN) to generate proposals, which are then fed into Fast R-CNN for detection.
Anchor-based methods
Many state-of-the-art detectors like Faster R-CNN, YOLO, etc., use anchor boxes of different aspect ratios as priors for object locations, scales, and aspect ratios during training. Anchors help the model converge faster and improve detection performance.
Model Architecture
Popular model architectures used for object detection include VGG, ResNet, Inception, etc. Deeper networks capture richer features but require more computational resources. Model architecture and design choices depend on accuracy and speed requirements.
Workflow of Object Detection
The general workflow for building an object detection model involves the following key steps:
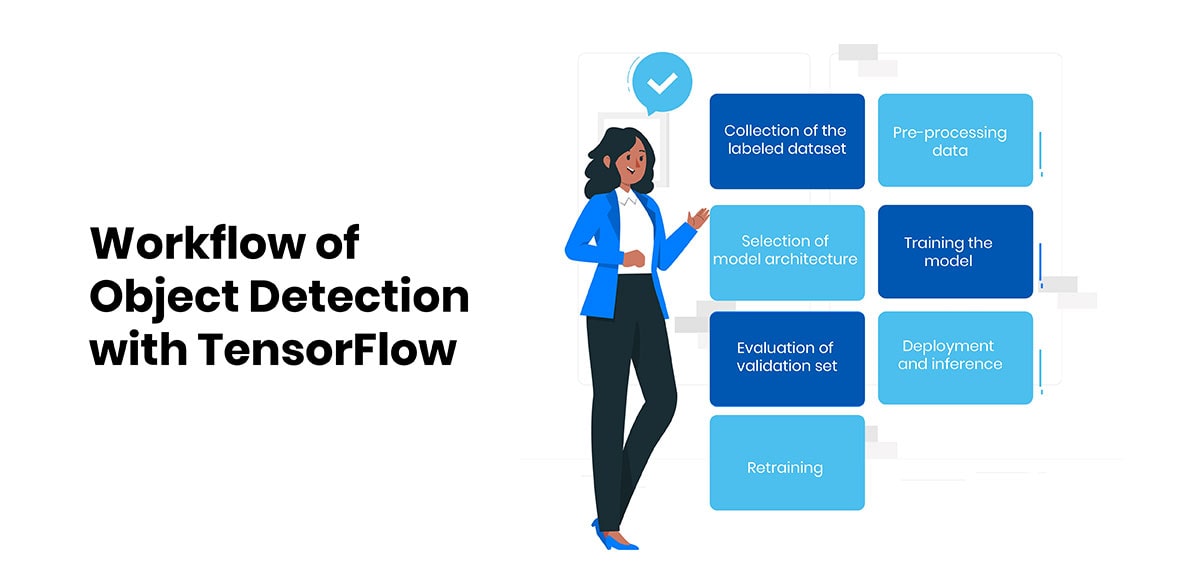
Collection of the labeled dataset
The general workflow for building an object detection model kicks off with the arduous task of data collection and annotation. In order to accurately train neural networks, they must be fed huge datasets containing real-world images brightly labeled with bounding boxes and class IDs. Open datasets such as MS COCO, PASCAL VOC, and Open Images that encompass common object categories across various contexts are conventionally tapped into. These pooled datasets pool together millions of images painstakingly annotated by humans, carving out the rough region proposals and pinpointing the precise object classes.
Pre-processing data
Once the richly annotated datasets have been aggregated, the images require preprocessing before feeding into models. Since deep learning algorithms can only chew inputs of fixed dimensions, the diverse resolutions of photos drawn from the wild web have to be homogenized. Standardization is brought about by resizing all images to expected input sizes around 300x300 or 600x600 based on the selected architecture. Other augmentations like randomly cropping patches and flipping orientations are also leveraged to artificially multiply the data and reduce overfitting.
Selection of model architecture
With real data at hand, designers opt for an object detection framework. Popular backbones such as VGG, ResNet, and MobileNet that have been finely tuned on ImageNet for image classification tasks are plugged in as feature extractors. On top of that, architectures specialized for localization like SSD, YOLO, and Faster R-CNN are bolted on, along with design choices involving anchor boxes. Model capacity, hyperparameters, and other nuances are tweaked based on the target domain.
Training the model
The fruitfully compiled models are then seriously trained end-to-end using the annotated datasets. Given an image, they are tasked with spitting out predicted class probabilities and refined bounding box coordinates for each detected object. The lost function throws а mathematical fit by contrasting these against human-supplied ground truths, minimizing differences. Optimization algorithms like SGD or Adam are harnessed to gradually diminish the loss by small parameter updates over many training iterations.
Evaluation of validation set
Once а satisfactory amount of sweating has been put in by GPU farms, the half-baked models must prove their mettle. They are put through extensive paces on а held-out validation set never seen during training. Mean average precision (mAP) scores that balance precision and recall become the key report card. Other metrics like loss values and detected box iou also provide а holistic assessment. Underperformers are weeded out or require retraining from scratch with tuned hyperparameters.
Deployment and inference
Top-performing models pass this selection phase and move closer to real-world deployment. Since production usually demands fast processing on constrained devices, models are optimized to be efficient and portable across platforms. Techniques like quantization, pruning, and dimension reduction are leveraged to shrink file sizes and accelerate inference. Containers encapsulate full workflows for seamless integration into applications and services.
Retraining
Lastly, even the battle-hardened models constantly need honing to stay relevant with changing data distributions over time. Continual retraining what's their knives against fresher image batches, gradually chipping away at failure cases. Domain shifts due to new obstruction types or capturing conditions are smoothly adapted to. In this manner, detection systems stay agile, ever-learning like their human masters to better serve real-time computer vision tasks.
Object Detection Using TensorFlow
Object detection using TensorFlow involves leveraging machine learning and deep learning techniques to identify and locate objects within images or video frames in real-time.
What is TensorFlow?
TensorFlow is an open-source machine learning framework developed by Google for numerical computation and deep learning. It uses dataflow graphs and symbolic computations to represent complex algorithms and computations in machine learning. TensorFlow is very flexible and can be deployed across а range of devices from mobile to desktops to servers. It supports various deep learning frameworks and has а large user base today, making it very popular for ML research and production.
What is the TensorFlow object detection API?
The TensorFlow Object Detection API is а flexible, open-source framework built on TensorFlow for developing and training object detection models. It provides pre-trained detection models trained on datasets like COCO and OpenImages for plug-and-play use. Developers can also easily create custom object detection models using popular architectures like SSD, Faster R-CNN, etc. The TensorFlow API handles data loading/preprocessing, anchor generation, post-processing, etc, so that researchers can focus on model architecture and training. Its model zoo provides а convenient starting point for many problems.
How does Object detection work using TensorFlow API?
Using the TensorFlow Object Detection API for real-time object detection generally involves the following steps:
-
1. Select a Pre-trained Detection Model
The TensorFlow Model Zoo provides a variety of pre-trained models. These models vary in terms of accuracy and speed, catering to different requirements.
-
SSD MobileNet v1 COCO: Suitable for applications needing fast inference.
-
Faster R-CNN Inception v2 COCO: Provides higher accuracy but at the cost of speed.
-
2. Verify the Model on Sample Images
Before deploying the model for real-time inference, it is crucial to verify that it works correctly on sample images.
Example Code:
import tensorflow as tf
import numpy as np
import cv2
from object_detection.utils import visualization_utils as vis_util
from object_detection.utils import ops as utils_ops
# Load a sample image
image = cv2.imread('sample_image.jpg')
# Load the model
detection_model = tf.saved_model.load('ssd_mobilenet_v1_coco/saved_model')
# Prepare the image for the model
input_tensor = tf.convert_to_tensor(image)
input_tensor = input_tensor[tf.newaxis, ...]
# Run inference
detections = detection_model(input_tensor)
# Extract detection results
boxes = detections[
'detection_boxes'
][0].numpy()
classes = detections['detection_classes'][0].numpy().astype(np.int64)
scores = detections['detection_scores'][0].numpy()
# Visualize the results
vis_util.visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imshow('Object Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
-
3. Prepare for Real-Time Inference with a Webcam
For real-time object detection, you need to read frames from a webcam using OpenCV.
Example Code:
import cv2
# Initialize webcam
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Error: Could not open webcam.")
exit()
-
4. Process Video Frames and Run Inference
Read frames from the webcam, preprocess them, and pass them through the detection model.
Example Code:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Convert the frame to a tensor
input_tensor = tf.convert_to_tensor(frame)
input_tensor = input_tensor[tf.newaxis, ...]
# Run inference
detections = detection_model(input_tensor)
# Extract detection results
boxes = detections['detection_boxes'][0].numpy()
classes = detections['detection_classes'][0].numpy().astype(np.int64)
scores = detections['detection_scores'][0].numpy()
# Visualize the results
vis_util.visualize_boxes_and_labels_on_image_array(
frame,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
line_thickness=8)
# Display the frame
cv2.imshow('Object Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
-
5. Visualize Detected Objects
The detected boxes and class labels are visualized on the original frames using bounding boxes and labels.
Visualization Example:
vis_util.visualize_boxes_and_labels_on_image_array(
frame,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
line_thickness=8)
-
6. Custom Training and Transfer Learning
The API supports custom training and transfer learning, allowing you to adapt pre-trained models for new datasets. This is particularly useful for specific applications where the default classes do not suffice.
Steps for Custom Training:
-
Prepare Your Dataset: Annotate images with object locations and classes.
-
Configure the Model: Adjust the configuration files for your dataset.
-
Train the Model: Use TensorFlow’s training scripts to fine-tune the pre-trained model.
Example for Custom Training Setup:
python model_main_tf2.py \
--pipeline_config_path=path/to/your/config/file.config \
--model_dir=path/to/save/model \
--alsologtostderr
Practical Example: Real-Time Object Detection with TensorFlow
Here is a complete example that combines all the steps for real-time object detection using a webcam and TensorFlow:
Complete Code:
import tensorflow as tf
import numpy as np
import cv2
from object_detection.utils import visualization_utils as vis_util
from object_detection.utils import label_map_util
# Load the model
detection_model = tf.saved_model.load('ssd_mobilenet_v1_coco/saved_model')
# Load the label map
category_index =
label_map_util.create_category_index_from_labelmap('mscoco_label_map.pbtxt', use_display_name=True)
# Initialize webcam
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Error: Could not open webcam.")
exit()
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Convert the frame to a tensor
input_tensor = tf.convert_to_tensor(frame)
input_tensor = input_tensor[tf.newaxis, ...]
# Run inference
detections = detection_model(input_tensor)
# Extract detection results
boxes = detections['detection_boxes'][0].numpy()
classes = detections['detection_classes'][0].numpy().astype(np.int64)
scores = detections['detection_scores'][0].numpy()
# Visualize the results
vis_util.visualize_boxes_and_labels_on_image_array(
frame,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
line_thickness=8)
# Display the frame
cv2.imshow('Object Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
The practical example provided will help you get started with integrating object detection into your projects.
Conclusion
In this article, we studied real-time object detection, which is an important capability of computer vision. We discussed different object-detection approaches and model-building workflows. We demonstrated how to perform accurate and fast object detection in real time using pre-trained models from TensorFlow's powerful Object Detection API.
Object detection is an active area of research, but systems developed using techniques described here offer а convenient starting point for incorporating this vision capability into many applications. The ease of model deployment and retraining offered by TensorFlow Object Detection API lowers the barrier to exploring problems involving visual scene understanding.




