How Transformer Models Work: Architecture, Attention & Applications

Artificial intelligence (AI) has advanced rapidly in recent years, thanks to breakthroughs in deep learning models. One such innovation that has revolutionized natural language processing (NLP) is the transformer neural network architecture.
First proposed in 2017, transformers have become the state-of-the-art technique for sequence-to-sequence modelling. They can easily capture complex relationships over long distances in text or speech data. Let's understand what transformer models are, their unique mechanisms, and real-world applications.
The Need for Transformers
Before transformers, recurrent neural networks (RNNs) were state-of-the-art for natural language processing tasks. RNNs process textual data sequentially, one token at a time. This allows them to develop representations of full sentences, modeling complex linguistic phenomena like sentiment and translation.
However, RNNs struggle with very long sequences. As sequences get longer, RNNs lose the ability to connect information from earlier parts to later parts. This is known as the vanishing gradient problem - the error signal decays rapidly as it gets propagated over many timesteps.
Attention Mechanism - The Key Insight
Transformers introduced a novel architecture that could handle long sequences without RNNs. The key insight was the attention mechanism.
Attention allows the model to focus on the most relevant parts of the input while processing it. For example, to predict the next word in a sentence, attention helps the model refer back to important context words anywhere in the sentence, regardless of distance. This helps with long-range dependencies.
The transformer allows parallelization as well, speeding up training. Combined, attention and parallelization allow transformers to outperform RNNs on tasks with long sequences, like translation and text summarization.
Now that we know why transformers are useful, let's go step-by-step into their architecture
Transformer Architecture
A transformer contains an encoder and a decoder. The encoder maps the input sequence to a higher dimensional space. The decoder then converts it back to the original space, translating input to target tokens. We'll understand both stages.
Encoder Stage
The encoder breaks down into six key steps:
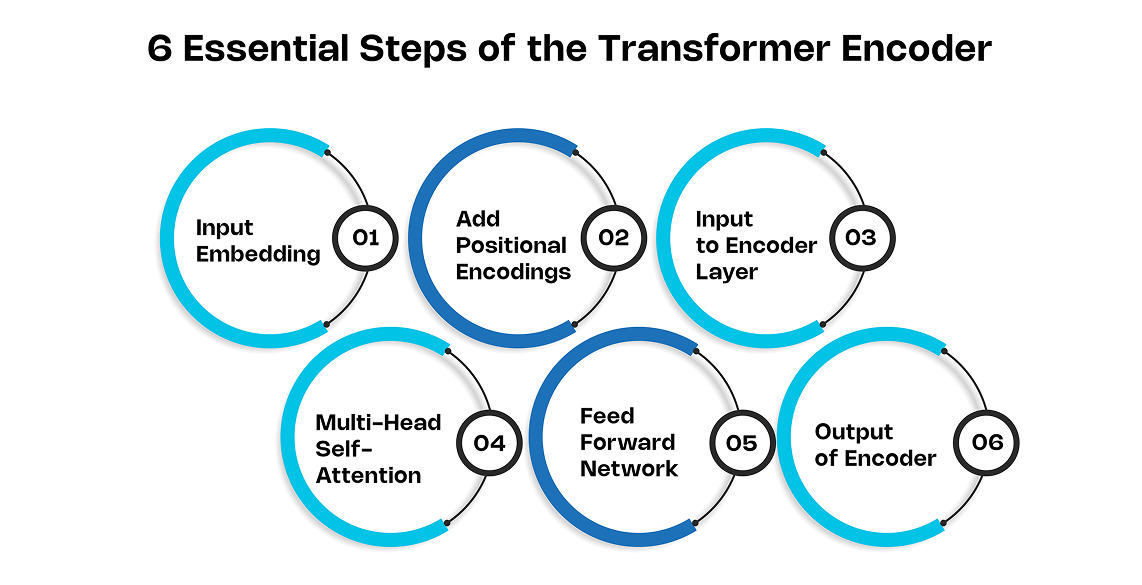
1. Input Embedding
The input sequence first passes through an embedding layer. This converts the discrete tokens like words or letters into vector representations based on their meaning. Each token gets mapped to a high dimensional embedding vector.
2. Add Positional Encodings
Unlike RNNs, transformers have no concept of sequence order. The embedding layer loses all positional information. Hence, we inject each embedding with positional encodings to restore their position. The encodings follow a specific pattern that allows the model to extrapolate to longer sequences.
3. Input to Encoder Layer
The combined input then goes into the main transformer encoder layer. The encodings help the model effectively relate the positional embeddings to each other.
4. Multi-Head Self-Attention
This is the key element that builds global dependencies between input and output. It calculates alignment scores between each token embedding and every other in parallel. The scores signify each token's contribution. Important words get higher scores.
5. Feed Forward Network
This simple feed-forward network further processes each token's representation separately.
6. Output of Encoder
The encoder outputs token-level representations carrying both contextual and positional information. These encodings capture intra-relationships in sequence.
Decoder Stage
The decoder is the second main component of the transformer architecture, along with the encoder. While the encoder maps the input sequence to a higher dimensional space, the decoder takes that representation and converts it back into the target output sequence. Essentially, the decoder inverts the operations of the encoder.
The decoder aims to map the encoder outputs to the target sequence we hope to generate at the output. For example, in machine translation from English to French, the encoder would process the English sequence while the decoder generates the French translation.
The decoder has a similar structure to the encoder, using multiple identical layers stacked on top of each other.
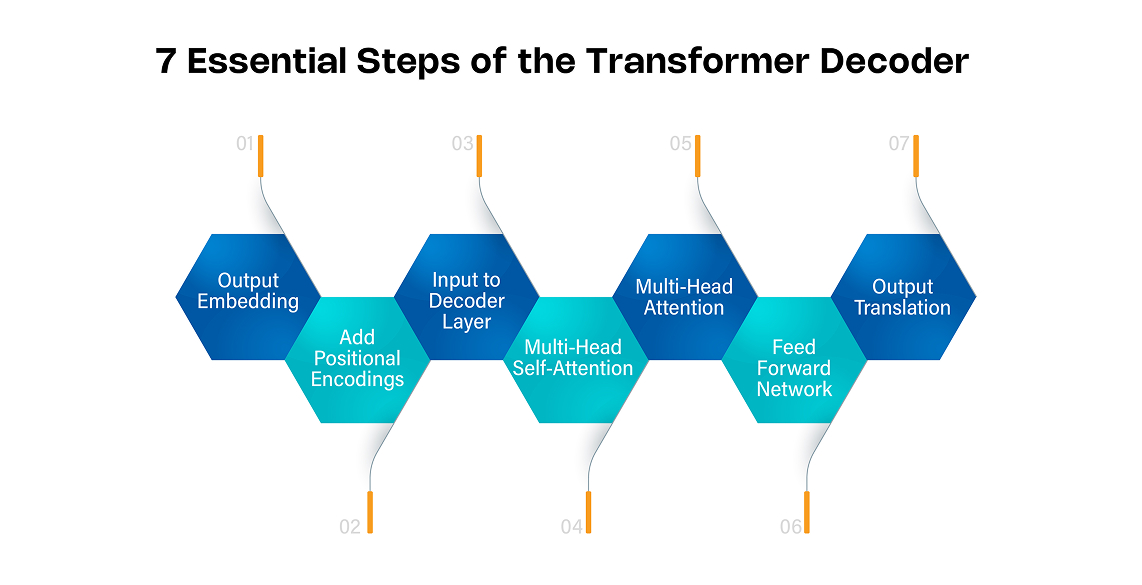
1. Output Embedding
The first step in the decoder is embedding the target output tokens, just like we embedded the input tokens in the encoder.
Specifically, the target sequence first passes through an embedding layer, which turns the discrete tokens, like words, into continuous vector representations. The embedding layer acts as a lookup table, mapping each token to its corresponding vector based on the embedding matrix.
These embeddings capture semantic similarities between tokens, allowing the model to generalize across related concepts. For instance, the word vectors for "cat" and "feline" would be very close together in the embedding space.
The dimensionality of the embedding layer determines the size of these token vectors. Typical values range from 128 to 1024 dimensions. Lower dimensionality leads to more compact models while higher dimensionality allows the network to learn more complex relationships.
In many cases, the decoder embedding matrix is initialized with the same weights as the encoder embedding matrix. This weight tying allows both components to share statistical strengths.
2. Add Positional Encodings
Next, we similarly add positional encodings to these embeddings, just as we did in the encoder. The positional encodings carry information about the position of each token in the sequence.
Adding positional information is crucial since the self-attention layers in the transformer have no innate concept of order, unlike recurrent models like LSTMs. The positional codes give the model a sense of which token came before or after another token.
There are different ways to represent positional information, like using sine and cosine functions of varying frequencies. These positional encodings have the same dimensionality as the embedding layer, so they can simply get summed with the token embeddings.
3. Input to Decoder Layer
After adding positional information, the decoder layer takes this embedded target sequence as input. Each token now has an embedding representing the token itself as well as a positional encoding representing the location of that token in the sequence.
The embedded target tokens get fed into the stacked decoder layers, with each layer performing operations to gradually build higher-level representations of the sequence.
4. Multi-Head Self-Attention
The first sublayer inside each decoder layer is a multi-head self-attention mechanism. This self-attention block allows each token in the target sequence to attend to all of the other tokens that came before it.
Specifically, each token can learn relationships and build context between itself and all previously generated tokens in the output sequence through self-attention weights. This gives the decoder a sense of the inter-dependencies within just the output sequence itself up to the current position.
For example, if we are translating the sentence "She walked slowly towards the cat", when generating the French translation for "slowly", the decoder can focus attention on the previous French words for "She" and "walked" to determine the proper agreement.
We use multi-head attention here to perform multiple parallel attention calculations, Learning different types of relationships in parallel leads to better modeling power.
Additionally, we mask the attention for any tokens after the current position, making sure no data from the future leaks through. Attention to the right is visible while attention to the left is always enabled. This prevents cheating by restricting what the prediction at each position can depend on.
5. Multi-Head Attention
After processing the relationships within the output sequence itself using self-attention, the second sub-layer applies multi-head attention on the encoder outputs.
This attention block takes queries from the decoder self-attention outputs and keys/values from the encoder stack outputs to focus on the most relevant encoder representations as needed to generate each output token.
In our translation example, to generate the French word for "cat", the decoder would pay the most attention to the encoder output corresponding to the English word "cat", establishing the mapping between the languages.
The attention weights coming out of this layer signify the contribution that each encoder output should have in generating the next decoder outputs. Tokens that provide contextual relevance to predicting the current token receive higher weights.
Again, we use multiple parallel attention heads, allowing the model to jointly attend based on different projections of queries, keys, and values to improve modeling accuracy.
6. Feed Forward Network
After incorporating relevant context from both the previously generated tokens and the input sequence tokens using multi-head attention blocks, we pass each representation through a simple feed-forward neural network.
This feed forward network further processes each token's attended representation separately and identically, with each token getting mapped to an output vector that summarizes all relevant information needed to predict the next token.
The feed forward layer is composed of two linear transformations with a ReLU activation between them. Additional nonlinearity allows the networks to learn more complex relationships.
7. Output Translation
Finally, the decoder outputs translated tokens autoregressively, one step at a time. At each step, the model predicts the next token by passing the previously generated embeddings and encoder outputs back into the decoder.
The output layer makes a prediction of the next token using the softmax function to convert scores for each token into probabilities. The token with the highest probability gets selected as the next output.
The decoder keeps generating translated tokens, feeding its own predictions back into itself token-by-token, until it produces the end-of-sentence token marking the translation is complete.
The entire architecture gets trained end-to-end, learning to map input sequences to target output sequences by optimizing the attention mechanism in AI to focus on the correct contextual relationships that minimize the translation loss across the dataset.
The transformer model thus understands complex global and local relationships using multi-head attention. The parallelizable structure also allows faster training than sequential RNNs.
Real-World Application
Transformer architecture has unlocked state-of-the-art results across NLP tasks. Its applications span:
Machine Translation
Transformer models like Google's BERT translate text between languages seamlessly using self-attention. They also enable real-time voice-to-text transcription.
Text Generation
OpenAI's GPT models use transformers to generate coherent long-form text on arbitrary topics automatically.
Question Answering
Transformer QA models like Google's BERT can answer factual questions on passages they have read with accuracy.
Summarization
Transformer architectures can digest lengthy text documents and condense their key points into readable summaries.
Sentiment Analysis
Leveraging self-attention, transformers can inference the sentiment of sentences, reviews, tweets etc. as positive, negative or neutral.
Limitations of Transformers
Transformers have opened up new possibilities but still face some issues:
Performance Decay on Extremely Long Sequences
One of the main limitations of transformers is that their performance tends to decay on extremely long input sequences. Specifically:
-
Attention and context still diminish over sequences with thousands of tokens. Even though transformers can process much longer sequences than previous recurrent and convolutional architectures, there are still limits.
-
As sequence length grows into the thousands of tokens, the proportion of the sequence that the model can attend to reduces. This reduces overall context and causes performance declines.
For example, a 2021 study, "Length-based Overfitting in Transformer Models" by Variš and Bojar found that transformer models achieve strong performance on sequences up to ~2,000 tokens. But at a length of 16,000 tokens, transformer models only attend to about 15% of the sequence.
This issue occurs because the computational complexity of attention grows quadratically with sequence length. So, processing longer sequences requires substantially more memory and compute resources.
There are solutions to mitigate this limitation, but they come with tradeoffs:
-
Sparse attention mechanisms have been developed which restrict each token to only attend to a local neighborhood of tokens. This reduces overall complexity. However, it also reduces model performance since less context is incorporated.
-
Long sequence transformers have also been created using sparse attention, with segment-level recurrence, and hierarchical representations. These preserve more context than standard sparse attention. But they still underperform compared to transformers without length restrictions.
So, while transformers offer clear gains on moderately long sequences of hundreds or low thousands of tokens, their performance inevitably decays on extremely long sequences. Efficient attention mechanisms help extend transformers to sequences with tens of thousands of tokens but come with reduced context. Overcoming this quadratic complexity of attention remains an open challenge.
Training Instability
Another limitation of transformers is that they can be unstable and fail to converge during training:
-
Transformers have more intrinsic difficulty with training stability compared to RNNs and CNNs. Without careful configuration and regularization, they often fail to solve tasks or match baseline performance.
-
Issues most frequently arise due to unstable gradients during optimization and overfitting on small datasets. The large parameter space of transformers contributes to these issues.
-
Solutions exist to ease training, like using smaller batch sizes, gradient norm clipping, dropout, attention regularization, and optimizer tweaking. However, transformer training still requires more precise configuration than past architectures.
-
Researchers have improved the stability of transformers through better initialization schemes, architectural modifications like using deep residual connections between layers, and novel regularizes. But base transformers remain sensitive.
So, in practice, properly training transformers can require extensive hyperparameter tuning and algorithmic modifications beyond what suffices for other neural networks. Models still frequently collapse to poor solutions without the appropriate stabilization measures. Advancements have eased but not solved these training stability problems.
Interpretability Issues
Finally, transformers share the prevalent limitation of interpretability with other deep learning models:
-
Understanding how transformers produce internal representations and predictions remains just as opaque and difficult as for all other neural networks.
-
Analysis methods like attention maps provide some coarse model interpretability. But deeper reasoning about information flows and decision boundaries defies explanation.
-
Interpretability issues limit the ability to detect model biases, ensure safety for sensitive applications, and diagnose poor generalization. Users must largely trust model behavior as a black box.
-
Techniques like distillation into decision trees or rule mining provide glimpses into model logic. But they fail to match the fidelity of transformers themselves and provide only approximate explanations.
So, in essence, transformer models exhibit the same lack of interpretability as all deep neural networks. They encode information in distributed numerical representations without clear semantics. This prevents intricate inspection and tuning of model behavior. Limited methods provide high-level interpretations but cannot unlock full model transparency and explainability.
Closing Thoughts
Transformers have been a game changer for sequential learning. Their attention approach builds both local and global relationships to tackle longer sequences. This is helping scale NLP models to new frontiers.
We hope this step-by-step explanation gives you an intuitive understanding of transformers under the hood. The applications discussed here are just the tip of the iceberg. These models hold great promise to automate language and speech applications. The future looks exciting as we unlock their full potential.




