How Speech-to-Text and Text-to-Speech Models Drive NLP Innovations

Voice assistants, audiobooks, and real-time transcriptions are part of daily life, thanks to advancements in natural language processing (NLP). At the heart of these technologies are text-to-speech models, which enable computers to understand and produce human-like speech. These NLP innovations are transforming industries, from healthcare to customer service, by making communication faster, more accessible, and more inclusive. This blog explains how speech-to-text models and text-to-speech models work, their key applications, challenges, and future potential.
What Are Speech-to-Text and Text-to-Speech Models?
Speech-to-text models (STT) and text-to-speech models (TTS) are powered by natural language processing, a branch of AI that helps computers understand and generate human language. These models handle the conversion between spoken and written language, enabling seamless human-machine interactions.
-
Speech-to-Text Models: These convert spoken words into written text. For example, when you dictate a message to your phone, an STT model transcribes your speech into text for emails or notes.
-
Text-to-Speech Models: These turn written text into spoken words. For instance, a navigation app reading directions aloud uses a TTS model to produce natural-sounding speech.
Both rely on NLP innovations like natural language understanding (NLU) and natural language generation (NLG). NLU helps models grasp the meaning, context, and intent of speech or text, while NLG creates coherent, human-like responses. Together, these technologies make voice assistants, transcription services, and accessibility tools possible.
How Speech-to-Text Models Work
Speech-to-text models transform spoken language into text through a multi-step process driven by natural language processing. Here’s how they work in simple terms:
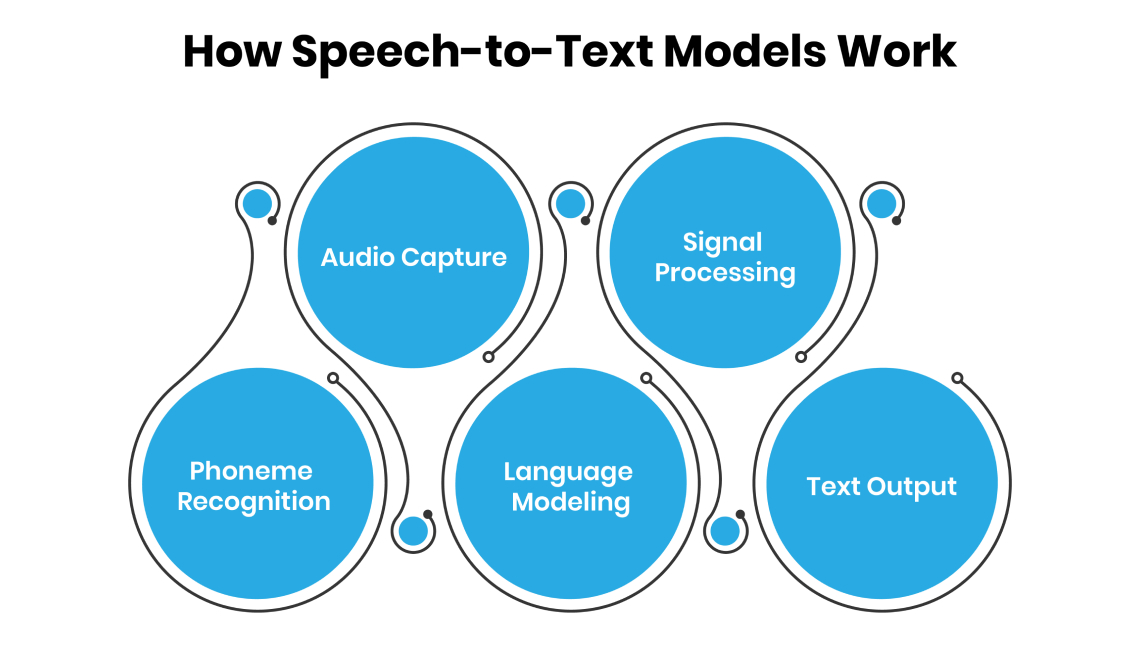
-
Audio Capture: A microphone records spoken words, turning sound waves into a digital signal.
-
Signal Processing: The system cleans the audio, removing background noise to focus on speech.
-
Phoneme Recognition: The audio is broken into phonemes, the smallest sound units in a language (e.g., “cat” has three phonemes: /k/, /æ/, /t/).
-
Language Modeling: Algorithms match phonemes to words and phrases, using context and grammar to ensure accuracy. Machine learning models, trained on massive audio datasets, improve recognition of accents and dialects.
-
Text Output: The system produces a written transcript, often in real-time, using Unicode to support multiple languages.
For example, a doctor dictating patient notes uses an STT model to transcribe speech into an electronic health record, saving time. Advanced speech-to-text models, like those improved by Google’s 2022 Speech-to-Text API, achieve high accuracy across 23 languages by using neural sequence-to-sequence models.
How Text-to-Speech Models Work
Text-to-speech models convert written text into spoken words, creating natural-sounding audio. The process involves several stages, powered by NLP innovations:
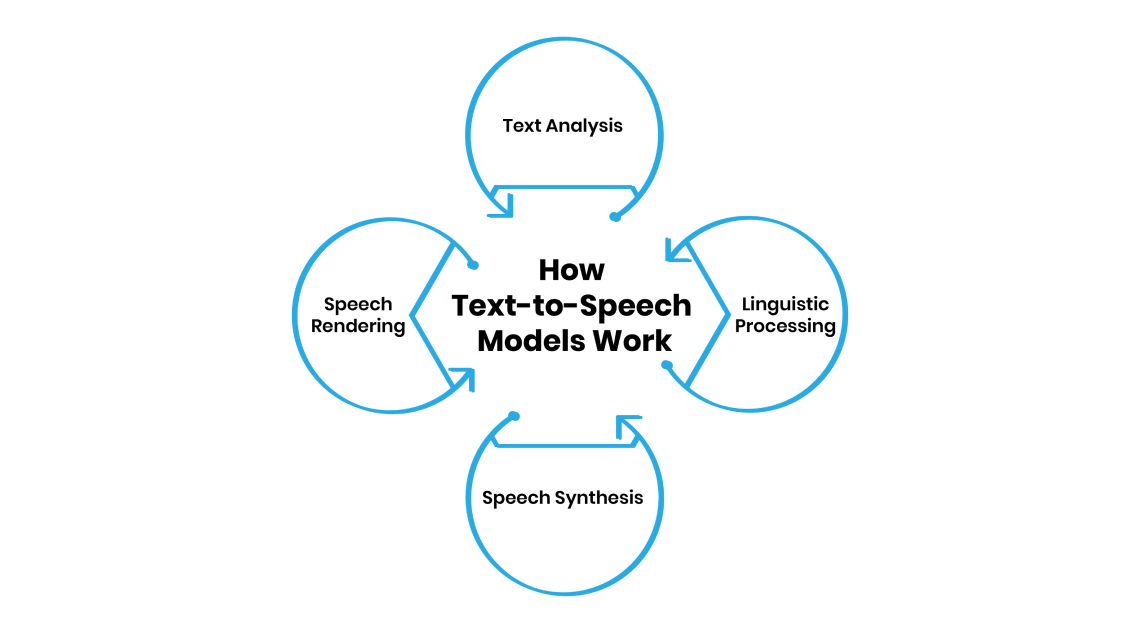
-
Text Analysis: The system breaks text into words, phrases, and sentences, understanding structure and meaning.
-
Linguistic Processing: It analyzes grammar, punctuation, and context to determine how the text should sound, including tone and rhythm.
-
Speech Synthesis: Using AI or pre-recorded voices, the system generates speech. Modern TTS models use AI to mimic human voices, adjusting pitch and speed.
-
Speech Rendering: The system fine-tunes pronunciation, emphasis, and pacing to make speech sound natural and engaging.
For example, a TTS model in an e-reader can read a book aloud in a human-like voice, helping visually impaired users.
Core NLP Innovations Behind STT and TTS
Natural language processing drives the success of speech-to-text and text-to-speech models through three key pillars: Natural Language Understanding (NLU), Natural Language Generation (NLG), and Continuous Learning. These innovations make voice AI accurate and versatile.
Pillar 1: Natural Language Understanding (NLU)
NLU enables models to understand the intent, context, and entities in speech or text. Its core components include:
-
Intent Recognition: Identifying what a user wants (e.g., “set a reminder” means creating a task).
-
Entity Extraction: Recognizing specific details, like names or dates (e.g., “meet Anna at 3 PM” extracts “Anna” and “3 PM”).
-
Context Management: Tracking conversation history to maintain coherence, such as remembering prior questions.
For example, a voice assistant understanding “Book a flight to Paris” relies on NLU to identify the intent (booking) and entities (Paris, flight).
Pillar 2: Natural Language Generation (NLG)
NLG creates human-like responses from processed data. Its components include:
-
Content Planning: Deciding what to say (e.g., confirming a booking).
-
Sentence Planning: Structuring responses grammatically (e.g., “Your flight to Paris is booked”).
-
Text Realization: Producing polished, natural output.
For instance, a TTS model in a customer service bot uses NLG to say, “Your order will arrive tomorrow,” in a clear, friendly tone.
Pillar 3: Continuous Learning and Adaptation
STT and TTS models improve over time by learning from user interactions and new data. This involves:
-
Feedback Mechanisms: Collecting user feedback to refine responses.
-
Error Analysis: Identifying mistakes, like misinterpreting accents, to improve accuracy.
-
Model Retraining: Updating models with new data to handle diverse languages or slang.
For example, a voice bot that mishears a regional accent can retrain on new audio samples to improve recognition.
These NLP innovations enable STT and TTS models to handle complex tasks, like multilingual support or sentiment analysis, making them essential for modern voice AI.
Applications Across Industries
Speech-to-text and text-to-speech models, powered by NLP innovations, are transforming industries by improving efficiency, accessibility, and user experience. Here are key applications:
Healthcare
-
STT: Doctors use speech-to-text models to dictate notes into electronic health records, reducing paperwork and allowing more patient time. For example, Cisco’s WebEx assistant transcribes meetings and provides captions.
-
TTS: Text-to-speech models read patient instructions aloud, helping those with visual impairments. These systems saved healthcare providers time during the COVID-19 pandemic by enabling contactless services.
Customer Service
-
STT: Interactive voice response (IVR) systems use speech-to-text models to understand customer queries, resolving 50% of calls without agents, saving millions annually.
-
TTS: Text-to-speech models power IVR responses, guiding callers in multiple languages with natural voices. Microsoft and Nuance’s IVR personalizes responses based on tone.
Education
-
TTS: Text-to-speech models turn textbooks into audiobooks, aiding students with dyslexia or visual impairments. They also help language learners with pronunciation.
-
STT: Speech-to-text models provide real-time feedback on pronunciation in language apps, improving fluency.
Retail and E-Commerce
-
STT: Speech-to-text models enable voice-based shopping, where users search for products via voice commands. In 2021, 60% of US shoppers used voice assistants for purchases.
-
TTS: Text-to-speech models provide product descriptions or confirm orders in a user’s preferred language, enhancing accessibility. Amazon’s Alexa is a prime example.
Media and Entertainment
-
TTS: Text-to-speech models create audiobooks and voiceovers for ads, saving costs compared to human actors.
-
STT: Speech-to-text models transcribe broadcasts or podcasts, providing captions for the hearing impaired.
Accessibility
-
TTS: Text-to-speech models, like Google’s TalkBack, read screen content for visually impaired users, improving digital access.
-
STT: Speech-to-text models allow hands-free operation for users with mobility issues, such as dictating commands.
These applications show how NLP innovations in STT and TTS models drive efficiency and inclusion across sectors.
Advantages of STT and TTS Models
Speech-to-text and text-to-speech models offer significant benefits, making them valuable for businesses and individuals:
-
Time Efficiency: STT automates transcription, saving hours on manual note-taking (e.g., healthcare documentation). TTS delivers instant audio output, like reading emails aloud.
-
Accessibility: TTS helps visually impaired or dyslexic users access content, while STT enables hands-free operation for those with mobility issues.
-
Cost Savings: TTS reduces the need for human voice actors, and STT cuts transcription costs. For example, Verint’s virtual assistant reduced call transfers by 20%, saving costs.
-
Multilingual Support: Both models support multiple languages, reaching global audiences. For instance, Amazon Transcribe supports over 70 languages.
-
Improved User Experience: Natural-sounding TTS and accurate STT enhance interactions, like JetBlue’s real-time voice analytics for customer service.
Challenges of STT and TTS Models
Despite their advancements, speech-to-text and text-to-speech models face challenges:
-
Accuracy Issues: STT struggles with noisy environments, accents, or homophones, with top systems achieving 80–85% accuracy compared to 99% for humans. TTS may mispronounce technical terms or lack emotional depth.
-
Context Understanding: Both models can misinterpret context, like STT confusing homophones (e.g., “buy” vs. “by”) or TTS missing emotional nuances.
-
Language Limitations: Some systems lack support for less common languages or dialects, limiting global reach.
-
Privacy Concerns: STT systems storing voice data raise privacy risks, requiring robust security.
-
Technical Complexity: Training and integrating models require diverse datasets and expertise, which can be costly.
Addressing these challenges is key to improving NLP innovations in voice AI.
Building and Integrating STT and TTS Models
Creating effective speech-to-text and text-to-speech models involves a structured process, as outlined by Techstack. Here’s a simplified guide:
1. Select the Right Tech Stack:
-
a. Choose tools based on your goals (e.g., transcription, voice assistant) and KPIs like accuracy or language support.
-
b. Ensure scalability and accessibility for diverse users, including those with impairments.
2. Collect and Prepare Data:
-
a. Gather diverse speech samples relevant to your industry, ensuring credibility and accuracy.
-
b. Avoid biases, like overrepresenting certain dialects, to ensure fairness.
3. Train and Test the Model:
-
a. Filter and preprocess data to remove errors.
-
b. Extract features like phonemes or word patterns.
-
c. Train the model using machine learning, avoiding overfitting with techniques like cross-validation.
-
d. Test accuracy, especially with homophones or accents.
4. Integrate into Applications:
-
a. Add STT to convert speech to text and TTS to generate responses.
-
b. Use a Minimum Viable Product (MVP) approach to test core functionality before full deployment.
5. Iterate and Improve:
-
a. Monitor user feedback and retrain models to enhance accuracy and adapt to new speech patterns.
For example, a retailer building a voice shopping assistant would collect multilingual speech samples, train an STT model for voice searches, and use a TTS model for responses, testing with users to refine performance.
Future Trends in STT and TTS Models
The future of speech-to-text and text-to-speech models lies in advanced NLP innovations, particularly speech-language models that combine STT and TTS into one system. These models, like Hume AI’s Octave, integrate emotional intelligence, voice customization, and natural speech generation, creating lifelike interactions. Key trends include:
-
Unified Models: Single systems handling both STT and TTS, like EVI 2, for seamless conversations.
-
Emotional Intelligence: Models like Octave mimic accents, tones, and emotions, enhancing user engagement.
-
Multilingual Expansion: Support for more languages and dialects, reaching underserved markets.
-
Real-Time Processing: Faster, more accurate STT and TTS for instant responses, as seen in Google’s 2022 API.
-
Accessibility Focus: Improved tools for disabilities, like real-time captions or expressive TTS voices.
These advancements will make voice AI more human-like, accessible, and impactful across industries.
Conclusion
Speech-to-text and text-to-speech models, powered by NLP innovations, are revolutionizing how we interact with technology. From transcribing medical notes to enabling voice shopping, these models enhance efficiency, accessibility, and global reach. Despite challenges like accuracy and privacy, ongoing advances are making them increasingly reliable and versatile. Whether for customer support, multilingual assistants, or applications in healthcare and education, STT and TTS models offer endless possibilities across industries.




